C++ Serialization Tests
Data object serialization in C++ has been something that's been bugging me for a long time. I'm developing a distributed memory management library named Kelpie in C++ that sits on top of an RDMA/RPC communication library for HPC named Nessie that's in C. Nessie is a solid library and does a number of low-level things that make my life easier and my code portable to different HPC platforms. However, since it's written in C, there have been a number of times where I've had to do awkward things to interface my C++ code to it. Serialization is one major sore point with me. Nessie uses XDR for serialization, which doesn't work with C++ strings, and just feels cumbersome. I decided to write up a little benchmark to measure how well different, popular serialization libraries performed so I could convince the Nessie developers to support something else.
Serialization Libraries
Serialization is the process of converting a data structure you're using into a contiguous series of bites that can be transported over the network and revived into an object on the remote side without any additional information. This process often takes into account hardware architecture differences between the source and destination (byte endianness and word widths), as well as conversions between different programming languages. Some serialization libraries use a definition file to generate code for your application, while others provide hooks for you to easily define how objects get serialized in your code. I experimented with four main serialization libraries in this experiment.
- XDR: XDR is a C-based serialization that was developed in the 1980's for NFS. Users define data structures and RPC handles in a file that rpcgen translates to C code. Interestingly, XDR defers the actual packing of data until the last possible minute, allowing it to place data in an outgoing buffer. Unfortunately, it uses malloc, does not understand C++ strings, and defaults to storing all values in a big-endian format (it was developed by Sun).
- Boost: Boost has a handy C++ serialization library that makes it trivial to instrument your code with serialization routines. It supports nesting and can use different encoders (e.g., binary or xml). Like a lot of Boost code, it has a reputation for being flexible by heavyweight.
- Cereal: Cereal is a C++11 "headers-only" library designed to be similar but faster to Boost's serialization library. The C++11 requirement wasn't a problem for me, though I did find that I had to make some changes to my code to switch from Boost to Cereal.
- Protocol Buffers: PB is an object-oriented serialization library developed by Google that focuses on performance and storage efficiency. Similar to XDR you define a definition file that a tool translates into (a lot of) code you can compile into your application. PB gives you data objects to use in your code with getters/setters. It feels much more invasive to me, but it gives PB the ability to do more sophisticated things internally (e.g., know when an object is only partially packed). PB has a reputation for being both fast and space efficient.
There are other serialization libraries out there that I've experimented with but excluded from this test (thrift, avro, capn proto, flat buffers, etc.). Each library requires a good bit of tinkering to setup and incorporate into a test. I'd like to revisit them at some point for a bigger comparison.
Experiments
I'm only interested in seeing how well these libraries perform when using the types of data structures I frequently ship in my Kelpie library. My messages usually send a small number of (integer) default values followed by a series of id/string data entries. The test program generates all the application data at start time and then proceeds to serialize different amounts of input by changing how many id/string data entries are packed. Packing for me involves all steps in converting my application's data into a buffer that my RDMA library can transmit. In Boost, Serial, and PB, this RDMA buffer requirement involves copying the packed data to a memory location that is suitable for transmission (XDR allows me to write directly to the buffer).
Measurements
In separate tests I measure the encode/decode times, as well the size of the packed data that would be transmitted over the network. The packed message size shows that PB performs compression and achieves a noticeable improvement over the other libraries at all sizes. Boost carries the most overhead. Message size is important to me in Kelpie, as there are sizable communication penalties if you can't fit a message in a single MTU. Beyond fitting everything into an MTU, the differences between the libraries aren't that significant.

Encoding/Decoding speed however, is very important to me as every step in the communication path counts towards the latency of my operations. I was surprised and impressed by both XDR and PB: they both performed well and were significantly better that Boost and Serial at the left end of the plot where I care the most.
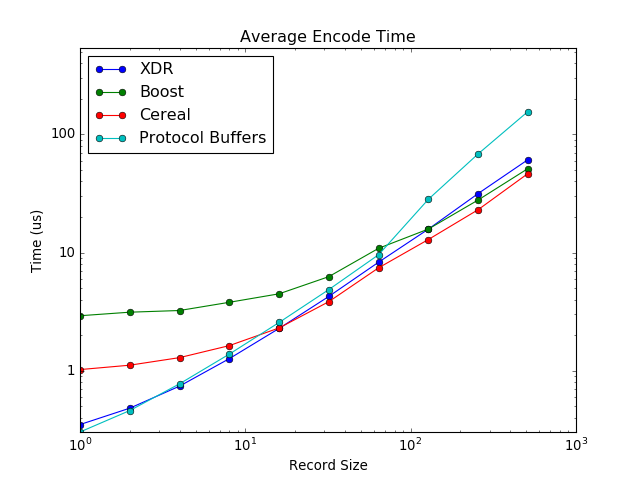
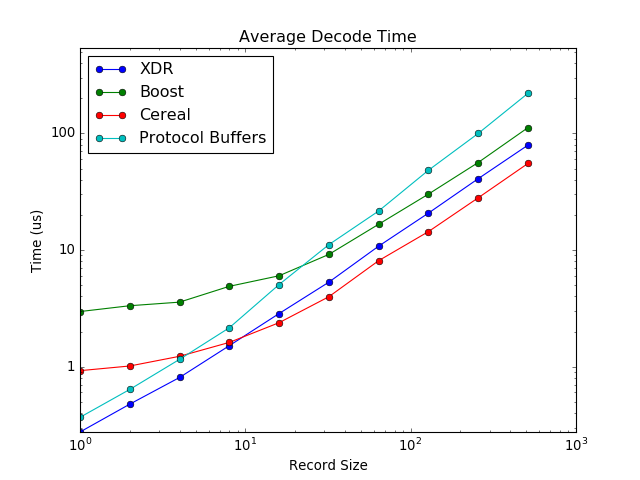
Decode times were another interesting story. XDR did very well for short messages and remained competitive with Cereal in larger messages. I was surprised PB did so poorly, even getting beat by Boost after 32 records were sent. Decode isn't as critical as encode (since the sender is free to do more work once the message leaves), but it does add to the communication cost.
Back to XDR?
I was pretty disappointed by these tests because I'd hoped that with all their shiny C++ features, newer libraries would outperform our aging XDR code. In some metrics that was true, but there was no universal winner in all situations: the air goes somewhere when you squeeze the balloon. It's important to point out here that these tests were designed to reflect my particular scenario, and are not meant to be an end-all test for comparing serialization libraries. Most people don't have my buffer challenges, and therefore would see different results. The best thing to do is code it up yourself and try it out with your own data.