Ray-Triangle Intersection in Hardware
One of the problems with porting complex algorithms to FPGAs is that there's never enough room in the chip to implement all of the logic you'd like to have in a design. For scientific computing kernels, you often want to implement a deep pipeline that cascades multiple floating point operations together in order to get good concurrency. Unfortunately, FPGAs lack native support for floating point and hand-packed FPUs consume a great deal of space. For the Virtex II/Pros, you roughly get about the same number of single-precision FP operations as the device number (e.g., V2P50 is about 30-50). At some point you have to accept that you have limited capacity and begin thinking of ways that you can re-use FP units to implement your calculation.

In 2005 I started looking at how I could shoe horn a ray-triangle intersection calculation into a medium-sized FPGA. I'd previously looked used a full-blown implementation of RTI to accelerate a key part of a photon mapping application we had previously developed for the Cray XD1. Rather than try to implement the whole data flow for the calculation as a single, continuous pipeline, we looked at using a fixed number of FP units that were reused to implement different portions of the pipeline.
Ray-Triangle Intersection
David Thompson and I previously looked at implementing a global illumination visualization application that generated realistic images through photon mapping techniques. Photon mapping is effectively the opposite of ray tracing: rather than trace the path of the eye back to light sources, you trace the paths of millions of individual photons from light sources to the eye. Photon mapping is time consuming because you need to bounce millions of photon around in a scene in order to provide enough data on how the photons light it. Steering the photons around the scene involves locating which polygon each photon will hit next. While polygons are usually organized in a way that minimizes the amount of collision testing that needs to be done for each photon, there are still a significant tests that need to be performed.

The Möller–Trumbore intersection algorithm provides a quick and concise way to calculate if and where a ray will intersect a triangle. With only about a dozen vector operations, MT is able to tell you whether an intersection will happen, how far the ray's origin is from the triangle (T), and where the intersection happens in the triangle (U,V). The data flow is eight layers deep and requires 54 floating point operations.

For the XD1 photon mapping application we implemented the RTI test in an FPGA. The software application stored a large number of triangles in the FPGA board's QDR memory and then streamed bundles of photons into the FPGA's on-chip BRAM. Upon receiving a new photon bundle, the hardware would perform a RTI test for each photon against every triangle to find which triangle was the closest hit for each photon. While the RTI unit had a very deep pipeline, there was plenty of work to keep it filled. It was extremely satisying to see the FPGA beating state-of-the-art Opterons, especially since it meant the Opterons were free to do other things in the XD1.
Scheduling to a Fixed Array
Following the XD1 work I started looking at whether we could build an FPGA design that could use a smaller number of floating point units that were statically scheduled to execute a data flow. To me, it was an interesting approach because it blended together ideas from reconfigurable computing and software. By using an FPGA we could define the number and type of FP units we wanted in the array, as well as how much buffering would be needed. However, we were programming the schedule of execution into the block rams of the chip. This would be especially handy if you wanted to have one hand-optimized hardware design perform different calculations.
I used some tools that I had developed the year before to model the calculation as a graph and explore how varying the number of FP units affected scheduling. This work helped show that the FP units were underutilized because of dependencies in the graph. In order to fill idle times, we packed two iterations of the algorithm into a single schedule. This work boosted our (roughly) 50% utilization estimates up to 75% without significant increases in hardware.

Adrian Javelo and I built parameterized hardware designs that allowed us to easily generate custom hardware implementations. We utilized a fixed array of FP units to implement the computations, and then attached muxes to each FP input to control how data was routed to the units. The muxes were customized to the application and were minimized to reduce routing requirements in the FPGA. Muxes were controlled by a simple table that was configured at build time.
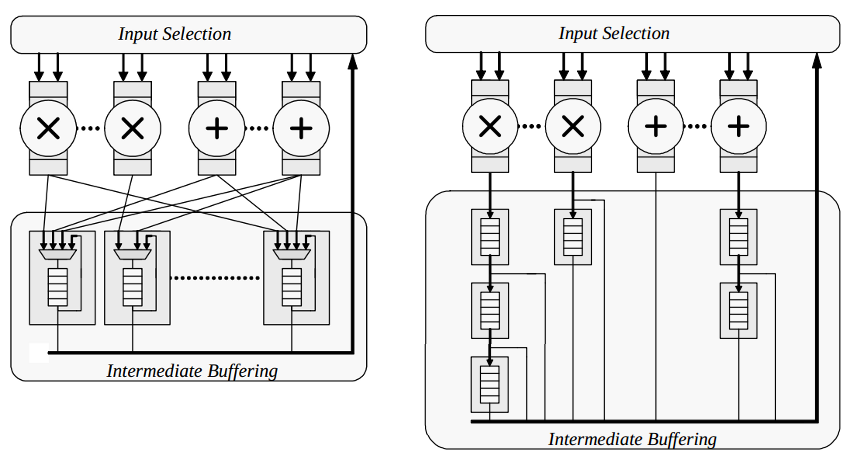
The results of the FP units generally needed to be buffered until they were needed. We decided that BRAMs wouldn't work for our needs because they only have two ports and it is often the case that more than one prior result from a particular FP unit is needed at a time. Our solution was to implement long delay registers that compactly mapped to the V2P's SRL16 primitive. We considered two approaches to buffering data: one where any FP unit could access any delay block, and another where delay blocks were a FP unit's results were streamed into a chain of delay units. While the latter approach required many more delay units, it wound up being 6% faster and 19% smaller than the independently accessible strategy.
Implementation
After we verified that the designs worked properly we did a study on how different design parameters affected real implementations. We adjusted the number of FP units and the number of iterations per block to measure the number of cycles required to complete 128 iterations of the algorithm. We also synthesized, placed, and routed the designs to get bounds on how fast the hardware would run.
It was a fun project and I really enjoyed developing tools that helped figure out how we should schedule the work on the FPGAs. We put a paper together for the ERSA conference, and received some distinguished paper title (forget what now, but the slides looked pretty).
Publications
ERSA Paper Craig Ulmer and Adrian Javelo, "Floating-Point Unit Reuse in an FPGA Implementation of a Ray-Triangle Intersection Algorithm", Engineering of Reconfigurable Systems and Algorithms, June 2006.
Presentations
ERSA Slides Slides I used at the conference