Contact Info
 |
Work Bio
Craig Ulmer is a Principal Member of the Technical Staff in the Scalable Modeling and Analysis group at Sandia National Laboratories in Livermore, California. He is the Principal Investigator of a DOE ASCR project that is exploring how data management and storage services used in high-performance computing (HPC) can be offloaded to new Smart Network Interface Cards (SmartNICs). He previously developed the FAODEL communication package to enable HPC workflows to route data between parallel simulation and analysis tools without having to relay it through the file system. In addition to scientific computing, Craig has had unique research experiences at Sandia involving storage-intensive computing, geospatial data warehousing, the Gov Clouds, cyber security, and custom hardware design.
Prior to joining Sandia, Craig received a Ph.D. in Electrical and Computer Engineering from the Georgia Institute of Technology for his work with low-level communication libraries for cluster computers. This research resulted in a flexible message layer for Myrinet named GRIM that enables users to efficiently utilize hardware accelerators and multimedia devices that are distributed throughout a cluster. While attending Georgia Tech, Craig completed intern and Co-Op work assignments at NASA's Jet Propulsion Laboratory, Eastman Kodak's Digital Technology Center, and IBM's EduQuest division.
Current Research Interests
SmartNICs and DPUs
Multiple network vendors have recently constructed Smart Network Interface Cards (SmartNICs) and Data Processing Units (DPUs) that enable users to place custom computations at the network's edge. As an HPC I/O researcher this hardware is appealing because it provides with an opportunity to migrate data management services and storage services (e.g., key/blob services such as Kelpie) to the local NIC and free up host memory and compute cycles for simulations. While we are currently a generation away from being able to perform compute-bound tasks on SmartNICs, our initial findings indicate that current SmartNICs such as the NVIDIA BlueField-2 are sufficient for implementing the asynchronous state machines that data management services use to commit data to remote memory and storage in the platform.
FAODEL: Communication Libraries for HPC Workflows
One challenge in implementing complex workflows on modern HPC platforms is that there isn't an easy and efficient way to route data between two or more parallel applications that are running on the platform at the same time. While some tools connect producers and consumers via TCP/IP connections, the majority of workflows simply handoff data by writing/reading files on the parallel file system. This approach incurs a significant amount of I/O overhead due to serialization and increases the strain on the platform's file system.
In Flexible, Asynchronous, Object Data-Exchange Libraries (FAODEL) our approach to solving this problem is to instead provide distributed memory services that make it easy a job to export in-memory data objects that other jobs can efficiently retrieve using RDMA mechanisms. Users specify a pool of nodes for hosting objects and then Publish/Get objects as needed. Unlike other implementations, a pool can exist in the producer job, a consumer job, a dedicated set of memory nodes, or even on a collection of SmartNICs. FAODEL is event-driven and allows requests for missing objects to block until they are published. FAODEL has been used at Sandia to checkpoint particle data, write/read mesh data through IOSS, and support the connecting of ML/AI applications to existing simulation workflows.
High-Performance Data Analytics (HPDA)
Many projects that I have worked on at Sandia have required a way to store, index, and analyze large amounts of data. While software frameworks such as Hadoop and Accumulo have made it easier to complete these objectives on commodity hardware, it has always been difficult to scale these frameworks up to take advantage of high-performance resources that are commonly found on HPC platforms. After running Sandia's first production Hadoop cluster for many years, we began looking at how we could build a better platform that would serve the growing needs of our data analytics users. The result is the Kahuna, a high-performance data analytics (HPDA) cluster that mixes HPC and big-data ideas. Kahuna provides 120 compute nodes, each with 256GB of memory, 700GB of local NVMe, and 56Gb/s InfiniBand networking. A separate 8-node Ceph cluster provides users with 1.5PB of centralized storage that can be accessed via POSIX, Rados, and RBD APIs over 10GigE.
The main challenge of running Kahuna though has been developing an environment where different communities can take advantage of the resources in new ways. We decided to abandon the Hadoop ecosystem and return to using Slurm for resource scheduling, and accepted responsibility for transitioning our big-data users over to this environment. For brute-force users we've had success with GNU Parallel on Slurm as well as through Slurm Job Arrays. For users that depend on specific frameworks (Spark, Jupyter) or services (postgreSQL, ephemeral NVME parallel file systems), we have written scripts to launch dependencies on demand in a Slurm allocation. Finally, the most important ingredient for a successful HPDA cluster is data. Part of our work involves finding and curating new, large datasests that would be of use to our analysts.
Analyzing Airplane Tracks
|
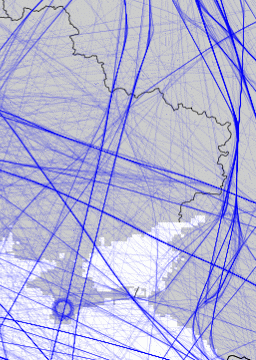
A personal hobby of mine is to collect and analyze airplane position datasets gathered from public sources. I initially ran an Amazon scraping campaign to gather data from a popular airplane website, but have since switched to using data from community sites. I collect data for the Bay Area using my own RTL/SDR ADSB receiver and have written tools to convert the point data to tracks and analyze it. Having long term data has allowed me to pull out interesting events, such as surveillance missions by both the Russians and the US. 
|
 |
Previous Work
- FPGA Hardware R&D: A significant part of my early Sandia work focused on leveraging field-programmable gate arrays (FPGAs) as computational accelerators. The initial portion of this work focused on chaining 50+ SNL-developed floating-point units together to implement custom computational pipelines to accelerate HPC applications. After learning how to use Xilinx's on-chip network transceivers, I built a SNORT-based network intrusion detection system for GigE, as well as a filter that removed malicious HTTP requests based on their similarity to common attack patterns. Other projects have earned me a classified inventor's award and NNSA recognition for discovering an obscure bug in a flight system through brute force simulation.
- Communication Software for Resource-Rich Clusters: My Ph.D. work with Dr. Sudhakar Yalamanchili involved the design and implementation of a low-level communication library named GRIM (General-purpose Reliable In-order Messages). GRIM was unique because it provided a robust way of exchanging data between processors, memory, and peripheral cards distributed throughout a cluster. Custom firmware was developed for the Myrinet Network Interface (NI) that allowed it to serve as a communication broker for the various resources in a host system. GRIM featured a rich set of communication primitives (remote DMA, active message, and NI-based multicast), but still managed to deliver low-latency, high-bandwidth performance.
- Wireless Sensor Networks: During my first summer internship at JPL, my mentor asked me to work through the logistics of deploying a large number of low-power, wireless sensor network (WSN) nodes on Mars. After interviewing a number of domain experts at JPL, I defined a basic set of requirements for a deployment and worked through the logistics for different deployment strategies (atmosphere scatter, tumbleweeds, hoppers). I then constructed WSN simulators to help explore different strategies for creating a routable network from the nodes. This work demonstrated that a campaign-style election system could partition the network in a distributed manner.
Last modified: August 14, 2021.