2005-02-01 Tue
fpga pub net security bestof
We published unclassified unlimited release (UUR) papers about implementing a GigE NIDS in an FPGA.

Publications
- IJE Paper Chris Clark, Craig Ulmer, and David Schimmel, "An FPGA-based Network Intrusion Detection System with On-Chip Network Interfaces", International Journal of Electronics, Vol. 93, Issue 6, 2006. link
- ARC Paper Chris Clark and Craig Ulmer, "Network Intrusion Detection Systems on FPGAs with On-Chip Network Interfaces", Applied Reconfigurable Computing, February 2005.
Presentations
- ARC Slides Presentation given at the Applied Reconfigurable Computing Conference.
2002-11-19 Tue
net fpga bestof pub
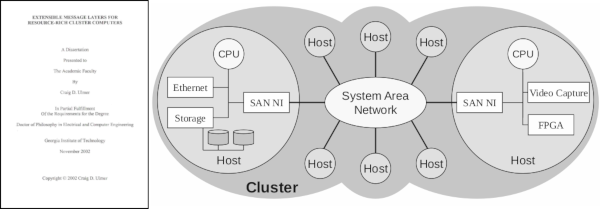
In November of 2002 I successfully defended my Ph.D. dissertation and received approval by my reading committee to publish it through Georgia Tech. Extensible Message Layers for Resource-Rich Cluster Computers describes how low-level communication layers can be constructed to enable users to leverage both the host processors and peripheral devices distributed in a cluster to complete work. Our approach embeds special functionality into the cluster's intelligent network interface cards to streamline the flow of data between resources. The General-purpose, Reliable, In-order Messages (GRIM) library provides a reference example on current generation hardware.
Official Version at Georgia Tech
Georgia Tech has the original copies of my dissertation on file. The GT library scanned the version I submitted and makes it available in this SMARTech Dissertation Record. A copy of it is available here:
- On-Record Dissertation (40MB, 249 double-spaced pages) Craig Ulmer Extensible Message Layers for Resource-Rich Cluster Computers, November 2002.
Update: Single-Spaced Version
The version of the dissertation that GT has on file is large and double-spaced. In 2020 I went back and made a more compact, single-spaced version. There are some format differences (e.g., references), but the content is the same:
You can also look at individual chapters:
Presentations
- Defense Slides The presentation slides I used during my defense
- Sandia Slides A variation of the slides I used in my defense when I interviewed at Sandia

Summary
Cluster computing is an alternative approach to supercomputing where a large number of commodity workstations are utilized as the processing elements in a multiprocessor system. These workstations are interconnected by high-performance system area network hardware and specially designed "message layer" communication software. In the current generation of cluster computers, researchers have optimized message layers for communication between the host CPUs in the cluster in order to provide scalable computing performance. However, the recent development of a number of high-performance peripheral devices challenges the notion that message layers should be designed in such a CPU-centric manner. Modern peripheral devices feature powerful embedded processing and storage capabilities that can be leveraged to boost the performance of distributed applications. These peripherals function as sources and sinks of application data, and in some cases, as computational accelerators for offloading host-CPU tasks.
As Moore's Law continues its relentless trend, there will continue to be a migration of computing power to peripheral devices. Future clusters will not appear anything like the clusters of today. They will be rich in connectivity and computing power that is deeply embedded in the distributed components of the cluster. We refer to this new generation of systems as resource-rich cluster computers. These systems differ from traditional clusters in that application processing takes place in both the host CPUs and the peripheral devices. While the semiconductor industry continues to alter the economies of scale, the system software that productively enables resource-rich clusters is sorely lagging. Specifically, current generation message layers are ill equipped to service the needs of resource-rich clusters, as they are not designed to utilize peripheral devices as globally accessible resources in a cluster. This thesis focuses on the challenge of designing extensible message layers for this new generation of resource-rich clusters. We are specifically concerned with making peripheral devices available as globally accessible resources in the context of a programming model that permits applications to effectively and efficiently exploit the capabilities afforded by resource-rich clusters. The key contributions of this thesis fall into two categories. The first includes design concepts and programming abstractions for structuring messages layers to integrate powerful peripheral devices into a globally accessible pool of resources. The second class of contributions is engineering solutions to the challenging problems of effectively and efficiently realizing these design concepts in a manner that tracks the evolution of technology, that is, the continued migration of computing power to distributed resources.
2002-06-28 Fri
net io pub
One problem I ran into on every PCI card that I worked with in grad school is that it takes a lot of work to transfer data from the host to the card efficiently. I wound up writing a library that implemented mutliple PIO data transfer tricks and added some mechanisms for it to select which injection method to use based on host performance.

Abstract
A key task for providing high performance in cluster computers is efficiently transferring data between cluster resources. This study focuses on one component of the communication pipeline: the host to peripheral card interface. As Moore's Law continues to progress, we are seeing successive generations of clusters with increasing compute power and communications bandwidth, but with roughly the same I/O systems. Communication software is continuously being re-optimized for each succeeding generation of hardware.
In this paper we describe a tunable library for host-to-device communication. The library profiles performance characteristics of the host's hardware environment and utilizes this information to automatically configure host-to-device transfer mechanisms. In addition to taking advantage of CPU-specific features, the library exposes I/O characteristics of individual peripheral devices in data transfer optimizations. The benefit of the library is demonstrated by providing measurements and experiences with three generations of clusters.
Publications
- PDPTA Paper Craig Ulmer and Sudhakar Yalamanchili, "A Tunable Communications Library for Data Injection", Parallel and Distributed Processing Techniques and Applications.
Presentations
2002-03-28 Thu
fpga net pub
Last year several of the Georgia Tech Systems professors from CS and ECE banded together to form the Center for Experimental Research in Computer Systems (CERCS). We've been lucky to have sponsors such as Intel fund our work and provide us with multiple clusters for our experiments. I helped out with the below poster about Active SANs work.

Poster
- CERCS Poster Poster about ASAN work presented at CERCS review


