2025-11-24 Mon
pub data seismic ai
We submitted an unclassified unlimited release (UUR) report to arXiv discussing our approach to improving multimodal data fusion accuracy by scaling the significance of each input dataset by a learned trust weight. This work uses seismic, SAR, streetview, and news report data sources about the 2020 Beirut warehouse explosion to estimate the magnitude of the blast.

Estimating Damage to the City from Streetview Images

Converting Streetview Photospheres to Planar Images
Abstract
The estimation of explosive yield from heterogeneous observational data presents fundamental challenges in inverse problems, particularly when combining traditional physical measurements with modern artificial intelligence-interpreted modalities. We present a novel Bayesian fractional posterior framework that fuses seismic waves, crater dimensions, synthetic aperture radar imagery, and vision-language model interpreted ground-level images to estimate the yield of the 2020 Beirut explosion. Unlike conventional approaches that may treat data sources equally, our method learns trust weights for each modality through a Dirichlet prior, automatically calibrating the relative information content of disparate observations. Applied to the Beirut explosion, the framework yields an estimate of 0.34-0.48 kt TNT equivalent, representing 12 to 17 percent detonation efficiency relative to the 2.75 kt theoretical maximum from the blast's stored ammonium nitrate. The fractional posterior approach demonstrates superior uncertainty quantification compared to single-modality estimates while providing robustness against systematic biases. This work establishes a principled framework for integrating qualitative assessments with quantitative physical measurements, with applications to explosion monitoring, disaster response, and forensic analysis.
Publication
- arXiv:2511.16816 Lekha Patel, Craig Ulmer, Stephen J. Verzi, Daniel J. Krofcheck, Indu Manickam, Asmeret Naugle, and Jaideep Ray, "Trust-Aware Multimodal Data Fusion for Yield Estimation: A Case Study of the 2020 Beirut Explosion", arXiv:2511.16816.
Our "Prototyping and Characterization of Advanced Environments for AI+HPC on Commodity Systems" poster that we presented at an internal workshop. This unclassified unlimited release (UUR) poster (SAND2025-01494C) is OSTI DOI 3018840.

- Poster Craig Ulmer, Benjamin Schwaller, Cory Lueninghoener, Patrick Carlson, Ryan Prescott, and Jim Brandt, "Prototyping and Characterization of Advanced Environments for AI+HPC on Commodity Systems", published as an unclassified unlimited release (UUR) poster. DOI https://doi.org/10.2172/3018840.
2024-09-27 Fri
pub hpc smartnics
Our ASCR SmartNIC project published the following unclassified unlimited release (UUR) paper (SAND2024-1022C) in IEEE Cluster.
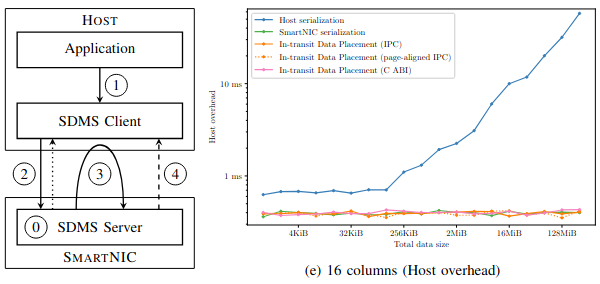
Abstract
Network interface controllers (NICs) with general-purpose compute capabilities ('SmartNICs') present an opportunity for reducing host application overheads by offloading non-critical tasks to the NIC. In addition to moving computation, offloading requires that associated data is also transferred to the NIC. To meet this need, we introduce a high-performance, general-purpose data movement service that facilitates the offloading of tasks to SmartNICs: The SmartNIC Data Movement Service (SDMS). SDMS provides near-line-rate transfer bandwidths between the host and NIC. Moreover, SDMS's In-transit Data Placement (IDP) feature can reduce (or even eliminate) the cost of serializing data on the NIC by performing the necessary data formatting during the transfer. To illustrate these capabilities, we provide an in-depth case study using SDMS to offload data management operations related to Apache Arrow, a popular data format standard. For single-column tables, SDMS can achieve more than 87% of baseline throughput for data buffers that are 128 KiB or larger (and more than 95% of baseline throughput for buffers that are 1 MiB or larger) while also nearly eliminating the host and SmartNIC overhead associated with Arrow operations.
Publication
- IEEE Cluster Paper Scott Levy, Whit Schonbein, and Craig Ulmer, "Leveraging High-Performance Data Transfer to Offload Data Management Tasks to SmartNICs". in IEEE International Conference on Cluster Computing (CLUSTER), September 2024.
2024-04-01 Mon
pub smartnics hpc
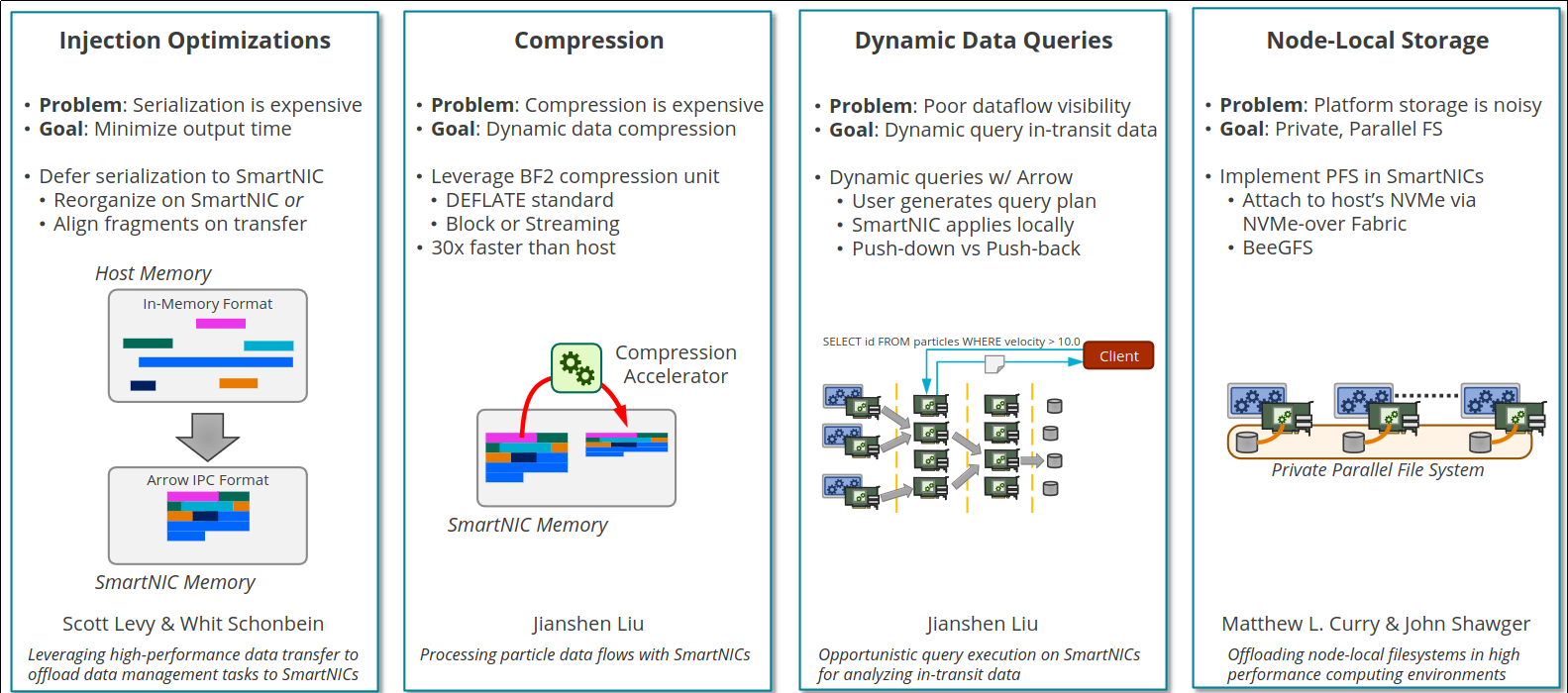
Our DOE ASCR-funded "Offloading Data Management Services to SmartNICS" project published this 144-page unclassified unlimited release (UUR) technical report.
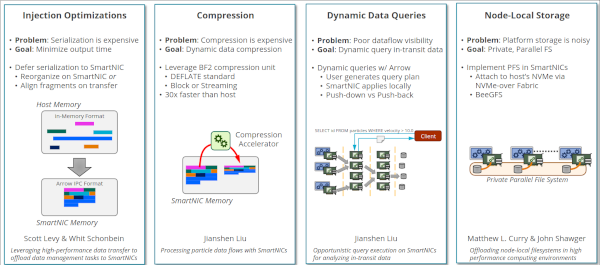
Abstract
Modern workflows for high-performance computing (HPC) platforms rely on data management and storage services (DMSSes) to migrate data between simulations, analysis tools, and storage systems. While DMSSes help researchers assemble complex pipelines from disjoint tools, they currently consume resources that ultimately increase the workflow's overall node count. In FY21-23 the DOE ASCR project "Offloading Data Management Services to SmartNICs" explored a new architectural option for addressing this problem: hosting services in programmable network interface cards (SmartNICs). This report summarizes our work in characterizing the NVIDIA BlueField-2 SmartNIC and defining a general environment for hosting services in compute-node SmartNICs that leverages Apache Arrow for data processing and Sandia's Faodel for communication. We discuss five different aspects of SmartNIC use. Performance experiments with Sandia's Glinda cluster indicate that while SmartNIC processors are an order of magnitude slower than servers, they offer an economical and power efficient alternative for hosting services.
Publication
- SAND Report Craig Ulmer, Jianshen Liu, Carlos Maltzahn, Aldrin Montana, Matthew L. Curry, Scott Levy, Whit Schonbein, and John Shawger, "Offloading Data Management Services to SmartNICs: Project Summary". SAND2024-03873, April 2024.
Presentations
- HPC Initiatives Slides: Presentation I gave at the SNL HPC Initiatives seminar in January.
- SRU Slides: Presentation I gave to an undergraduate Computer Engineering class at Slippery Rock University in October.
2023-10-04 Wed
pub hpc smartnics
We published this unclassified unlimited release (UUR) technical report about the Glinda HPDA cluster.

The Glinda Cluster
Abstract
Sandia National Laboratories relies on high-performance data analytics (HPDA) platforms to solve data-intensive problems in a variety of national security mission spaces. In a 2021 survey of HPDA users at Sandia, data scientists confirmed that their workloads had largely shifted from CPUs to GPUs and indicated that there was a growing need for a broader range of GPU capabilities at Sandia. While the multi-GPU DGX systems that Sandia employs are essential for large-scale training runs, researchers noted that there was also a need for a pool of single-GPU compute nodes where users could iterate on smaller-scale problems and refine their algorithms.
In response to this need, Sandia procured a new 126-node HPDA research cluster named Glinda at the end of FY2021. A Glinda compute node features a single-socket, 32-core, AMD Zen3 processor with 512GB of DRAM and an NVIDIA A100 GPU with 40GB of HBM2 memory. Nodes connect to a 100Gb/s InfiniBand fabric through an NVIDIA BlueField-2 VPI SmartNIC. The SmartNIC includes eight Arm A72 processor cores and 16GB of DRAM that network researchers can use to offload HPDA services. The Glinda cluster is adjacent to the existing Kahuna HPDA cluster and shares its storage and administrative resources.
This report summarizes our experiences in procuring, installing, and maintaining the Glinda cluster during the first two years of its service. The intent of this document is twofold. First, we aim to help other system architects make better-informed decisions about deploying HPDA systems with GPUs and SmartNICs. This report lists challenges we had to overcome to bring the system to a working state and includes practical information about incorporating SmartNICs into the computing environment. Second, we provide detailed platform information about Glinda's architecture to help Glinda's users make better use of the hardware.
Publication
- SAND Report Craig Ulmer, Jerry Friesen, and Joseph Kenny, "Glinda: An HPDA CLuster with Ampere A100 GPUs and BlueField-2 VPI SmartNICs". SAND2023-10451, October 2023.