We published an unclassified unlimited release (UUR) paper.
Abstract
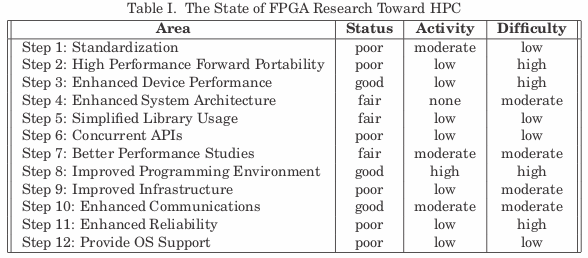
The field of high performance computing (HPC) currently abounds with excitement about the potential of a broad class of things called accelerators. And, yet, few accelerator based systems are being deployed in general purpose HPC environments. Why is that? This article explores the challenges that accelerators face in the HPC world, with a specific focus on FPGA based systems. We begin with an overview of the characteristics and challenges of typical HPC systems and applications and discuss why FPGAs have the potential to have a significant impact. The bulk of the article is focused on twelve specific areas where FPGA researchers can make contributions to hasten the adoption of FPGAs in HPC environments.
Publications
- TORTS Paper Keith D. Underwood, K. Scott Hemmert, and Craig D. Ulmer, "From Silicon to Science: The Long Road to Production Reconfigurable Supercomputing", ACM Transactions on Reconfigurable Technology and Systems, Vol. 2, No. 4, Article 26, September 2009.
2009-05-06 Wed
hpc io pub
We published an unclassified unlimited release (UUR) paper.

Abstract
Partitioning massively parallel supercomputers into service nodes running a full-fledged OS and compute nodes running a lightweight kernel has many well-known advantages but renders it difficult to access externally located resources such as high-performance databases that may only communicate via TCP. We describe an implementation of a proxy service that allows service nodes to act as a relay for SQL requests issued by processes running on the compute nodes. This implementation allows us to move toward using HPC systems for scalable informatics on large data sets that simply cannot be processed on smaller machines.
Publications
- CUG Paper Ron Oldfield, Andy Wilson, George Davidson, Craig Ulmer, and Todd Kordenbrock, "Access to External Resources Using Service-Node Proxies", Cray User Group
Presentations
2008-11-08 Sat
mesh code pub
We published an unclassified unlimited release (UUR) technical report and received permission to release the software.

Publications
- SAND Report Wendy Doyle, Ann Gentile, Philip Kegelmeyer, and Craig Ulmer "FCLib: The Feature Characterization Library". Sandia Report SAND2008-7687.
Code
We presented this unclassified unlimited release (UUR) poster/paper.

Publications
- HPEC Paper Craig Ulmer and Maya Gokhale, "Threading Opportunities in High-Performance Flash-Memory Storage", High-Performance Embedded Computing 2008.
Presentations
- HPEC Poster Poster I presented at HPEC. Maya and John May also presented this poster at PDSW08
- HPEC Overview A 2-minute overview I gave at the conference
We published this unclassified unlimited release (UUR) article.

Abstract
Data-intensive problems challenge conventional computing architectures with demanding CPU, memory, and I/O requirements. Experiments with three benchmarks suggest that emerging hardware technologies can significantly boost performance of a wide range of applications by increasing compute cycles and bandwidth and reducing latency.
Publication
- IEEE Computer Paper Maya Gokhale, Jonathan Cohen, Andy Yoo, W. Marcus Miller, Arpith Jacob, Craig Ulmer, and Roger Pearce, "Hardware Technologies for High-Performance Data-Intensive Computing", in IEEE Computer vol. 41, Issue 4, April 2008.